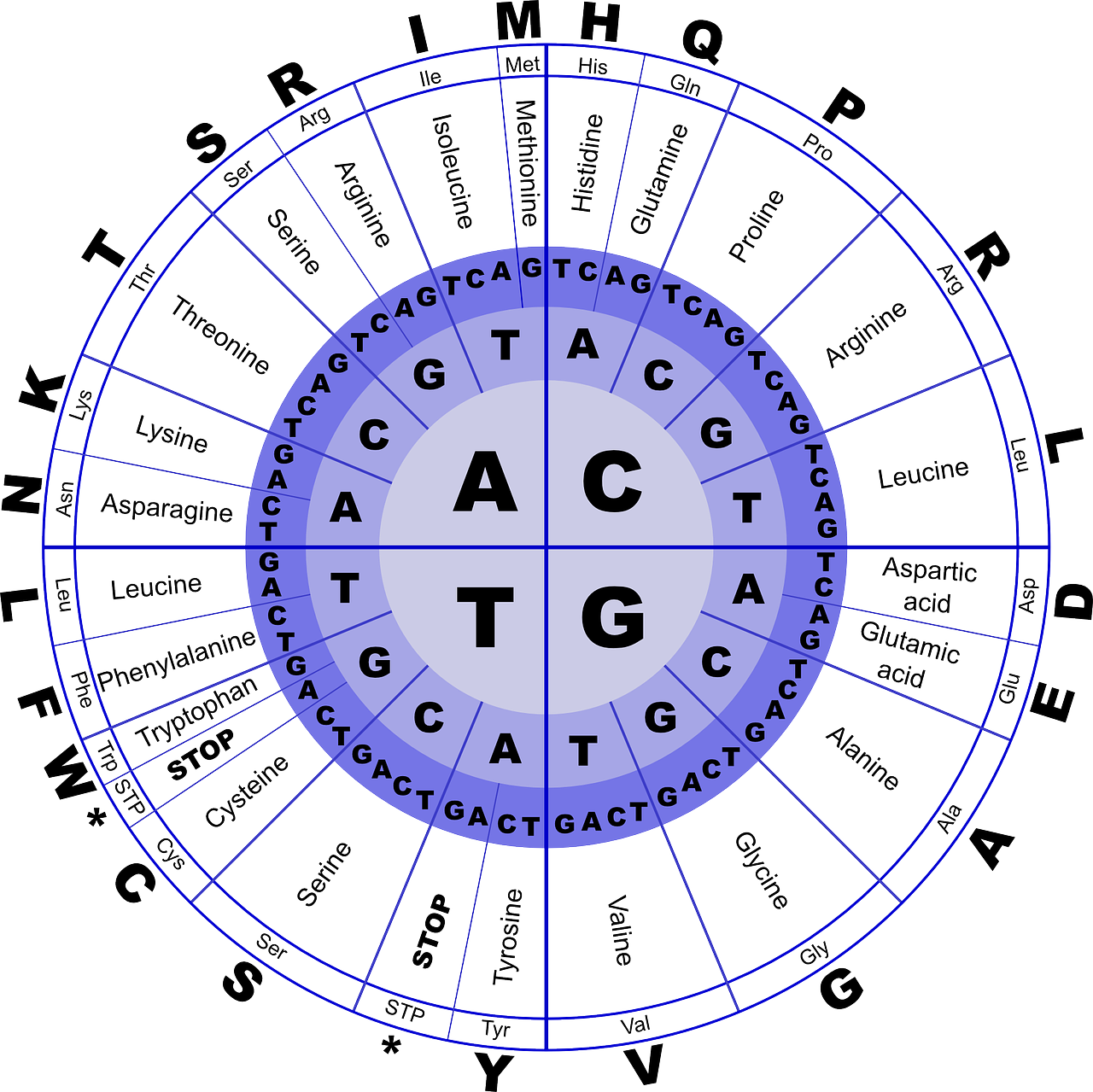
Genetic Code
The deciphering of the genetic code was indeed a monumental achievement in the field of biology. It allowed scientists to understand how the sequence of nucleotides in DNA and RNA corresponds to the sequence of amino acids in proteins. Here are some key points regarding the genetic code:
Codons: The genetic code is a set of rules that specifies the correspondence between nucleotide triplets (codons) in mRNA and the amino acids they code for. Each codon consists of three nucleotides, and there are 64 possible codons (4 nucleotide bases raised to the power of 3).
Amino Acids: There are 20 standard amino acids commonly found in proteins. Some amino acids are encoded by multiple codons, while others are specified by a single codon.
Start and Stop Codons: The genetic code includes start codons (AUG) that signal the beginning of protein synthesis, and stop codons (UAA, UAG, and UGA) that indicate the end of translation.
Universal Code: The genetic code is nearly universal across all living organisms. This means that the same codons typically code for the same amino acids in different species. It is a highly conserved feature of biology.
Triplet Code: The concept of a triplet code, where each codon consists of three nucleotides, was central to deciphering the genetic code. George Gamow’s idea that a triplet code was used for translating nucleotides into amino acids laid the foundation for this understanding.
Experimental Methods: Scientists like Marshall Nirenberg and Har Gobind Khorana played crucial roles in deciphering the genetic code. They used chemical and enzymatic methods to synthesize RNA with defined sequences and test how different sequences of mRNA were translated into specific amino acids.
Checker-Board: The checker-board you mentioned likely refers to a table that shows the correspondence between codons and the amino acids they represent. This table, known as the genetic code table, is a fundamental reference in molecular biology.
The elucidation of the genetic code was a significant breakthrough that paved the way for our understanding of how genetic information is translated into the building blocks of life, proteins. It also opened up avenues for genetic engineering, biotechnology, and many other areas of research and application in biology.
The concept of frameshift mutation
Frameshift mutations occur when one or more nucleotide bases are inserted or deleted from a DNA sequence. These mutations can have a significant impact on the reading frame of the genetic code and can result in the production of a nonfunctional or altered protein.
Frameshift Mutation: Frameshift mutations occur when the number of inserted or deleted nucleotides is not a multiple of three. This disrupts the triplet codon reading frame during translation.
Impact on the Reading Frame: As you mentioned in your example, inserting or deleting one or two bases shifts the reading frame, causing the entire sequence of codons to change. This leads to the synthesis of a completely different amino acid sequence and often results in a nonfunctional or truncated protein.
Insertions and Deletions: Frameshift mutations can result from either insertions (adding extra bases) or deletions (removing bases) within the DNA sequence.
Amino Acid Sequence: In the context of protein synthesis, frameshift mutations can lead to the production of a protein with an entirely different amino acid sequence. This can affect the protein’s structure and function, potentially causing a loss of function or a gain of new properties.
Sickle Cell Anemia Example: The example you provided earlier about the beta globin gene mutation causing sickle cell anemia is a classic case of a point mutation leading to a frameshift and a change in the protein structure, in this case, hemoglobin.
Frameshift mutations are one of the various types of genetic mutations that can occur in DNA. They can have a profound impact on the resulting protein and can be responsible for various genetic disorders or diseases.
tRNA– the Adapter Molecule
Transfer RNA (tRNA) serves as an essential adapter molecule in the process of translation. It plays a crucial role in deciphering the genetic code and linking it to the specific amino acids that are needed to assemble a polypeptide chain.
Anticodon Loop: Each tRNA molecule has an anticodon loop that contains three nucleotides. These three nucleotides, known as the anticodon, are complementary to the codons on the mRNA strand. This allows tRNA to recognize and bind to the specific codons on the mRNA during translation.
Amino Acid Binding: At the opposite end of the tRNA molecule is the amino acid acceptor end. This end binds to a specific amino acid, and the binding is highly specific. Each type of tRNA is associated with a particular amino acid, ensuring the accurate pairing of codons and amino acids.
Specificity: There are different tRNA molecules for each of the 20 standard amino acids. These tRNAs are highly specific for their corresponding amino acids and codons, ensuring that the correct amino acid is incorporated into the growing polypeptide chain.
Initiator tRNA: For translation initiation, a specific tRNA molecule called the initiator tRNA is used. It carries the amino acid methionine and binds to the start codon (AUG) on the mRNA.
Translation Termination: While tRNA molecules are responsible for recognizing codons that specify amino acids, there are no specific tRNA molecules for the stop codons (UAA, UAG, UGA). Instead, release factors recognize these stop codons and signal the termination of translation.
Secondary Structure: The typical secondary structure of a tRNA molecule is often depicted as a clover-leaf shape, but in reality, tRNA molecules have a more compact, three-dimensional structure. They form an inverted L-like shape, with the anticodon loop at one end and the amino acid acceptor end at the other.
Translation Accuracy: The accuracy of translation relies on the precise pairing of tRNA anticodons with mRNA codons. This fidelity ensures that the correct amino acids are added to the growing polypeptide chain.
tRNA plays a critical role in the translation process, ensuring that the genetic code is accurately read and that the appropriate amino acids are incorporated into the protein being synthesized.


